SeamlessM4T是MetaAI於2023年發佈的統整型機器轉譯系統,包含ASR(Automatic Speech Recognition)、T2TT(Text-to-Text Translation)、S2TT(Speech-to-Text translation)、T2ST(Text-to-Speech translation)及S2ST(Speech-to-Speech Translation)五種模型。在此探討SeamlessM4T工作流程,包含前處理SeamlessAlign模型。
圖片來自Meta AI, §UC Berkeley, “SeamlessM4T—Massively Multilingual & Multimodal Machine Translation”
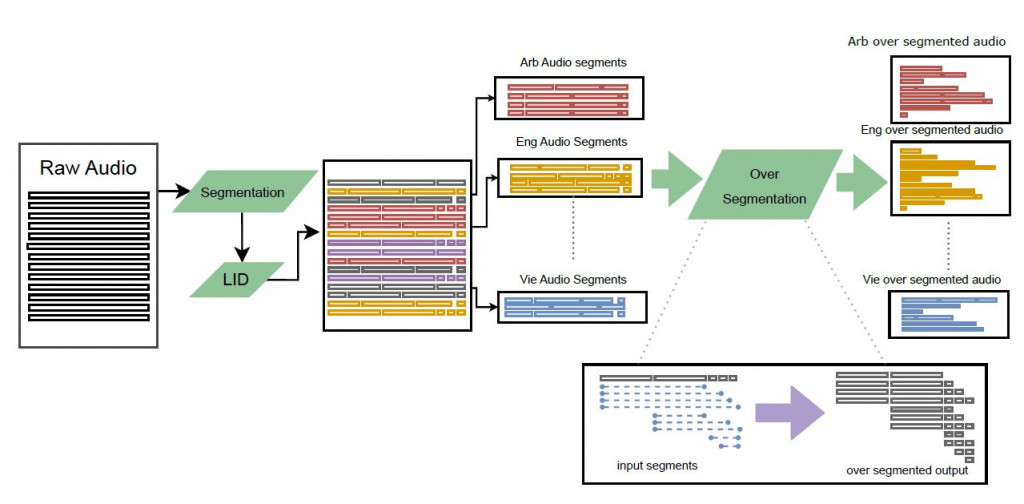
SeamlessAlign是MetaAI所開發現今最大多模型轉譯系統的開源數據集,內含總計270,000小時的語音數據,且能自動生成語音對齊數據。將大量原始重疊語音分開並用語言辨識(Language IDentification, LID)區分語言別。在文本方面使用跟 NLLB(No Language Left Behind)一樣的分句資料集。然後將語音和文本語料庫投影到一個共同的嵌入空間,在其中進行探勘以辨識最佳的分割組合。
圖片來自Meta AI, §UC Berkeley, “SeamlessM4T—Massively Multilingual & Multimodal Machine Translation”
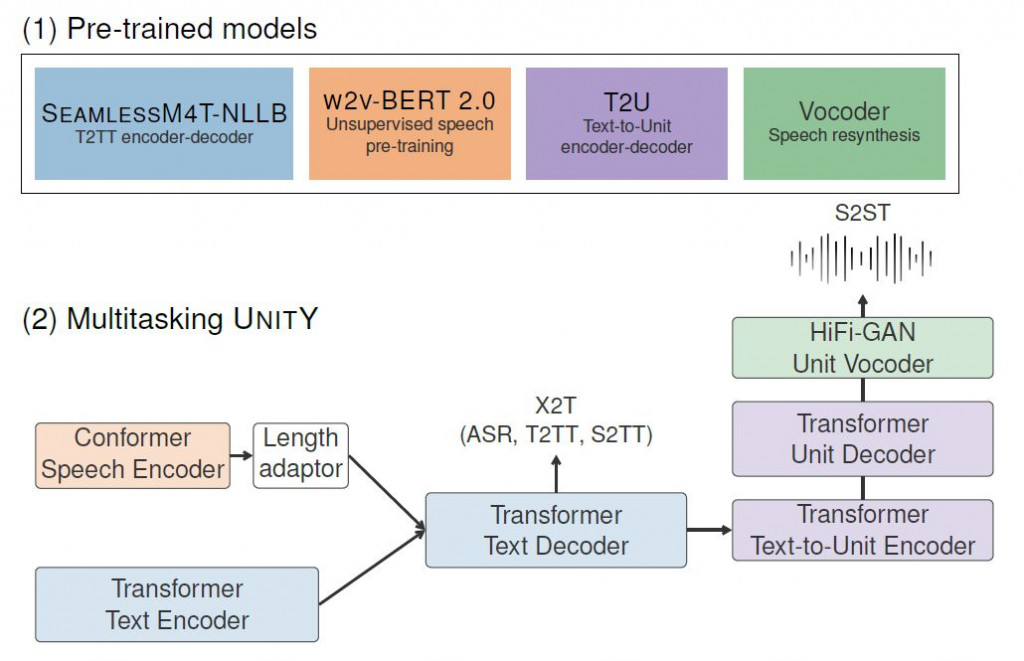
上圖呈現SeamlessM4T的工作流程,使用四個預訓練模型:
將SeamlessAlign得到的最佳分割組合送進Conformer(Convolution-augmented Transformer)語音編碼器或Transformer文本編碼器,經過Transformer文本解碼器即完成ASR、T2TT、S2TT模型流程。若再繼續經過Transformer Text-to-Unit編碼器還有Transformer Unit解碼器,最後利用高傳真生成對抗聲碼器,即完成S2ST流程。
SeamlessM4T的語音數據處理流程不複雜,前置作業有二:1) 用SeamlessAlign將原始音頻數據做前處理,區別數據中的語言,並對齊數據的長度、維度、分割組合等參數。2) 備好四種預訓練模型,SeamlessM4T-NLLB作為文本的編碼-解碼器;w2v-BERT 2.0非監督模型作為語音編碼器;T2U作為文本對Unit的編碼-解碼器;Vocoder為聲音合成之聲碼器。
接著正式進入轉譯流程,語音及文本數據分別編碼好後,送進已訓練好的SeamlessM4T-NLLB模型作解碼,即可完成ASR(Automatic Speech Recognition)、T2TT(Text-to-Text Translation)、S2TT(Speech-to-Text translation)的任務。而後再依序作Text-to-Unit、Unit解碼,最後用對抗生成Unit聲碼器編譯為語音訊號,即完成S2ST或T2ST任務。然而看似簡單的流程其實內含複雜的程式碼,本篇文章讓筆者了解大致流程,知道各流程的重點以利後續細部研究。


 iThome鐵人賽
iThome鐵人賽